Accessing and Modifying a String
String Indices
각각의 문자를 저장하기 위해 다른 양의 메모리를 요구할 수 있기 때문에
Swift에서 문자열은 정수 값으로 Index를 생성할 수 없다.
startIndex를 통해 문자열의 첫 문자에 접근할 수 있지만
endIndex는 마지막 문자 다음 위치를 나타내기 때문에 유효하지 않다.
그리고 빈 문자열이라면 startIndex와 endIndex는 동일하다.
문자열의 index(before:)와 index(after:) 메서드를 이용해 문자열의 인덱스에 접근할 수 있고
index(_:offsetBy:) 메서드를 통해 주어진 인덱스로부터 여러 문자를 한 번에 넘어갈 수 있다.
let greeting = "Guten Tag!"
print(greeting[greeting.startIndex])
// G
print(greeting[greeting.index(before: greeting.endIndex)])
// !
print(greeting[greeting.index(after: greeting.startIndex)])
// u
let index = greeting.index(greeting.startIndex, offsetBy: 7)
print(greeting[index])
// a
범위를 벗어난 Index 접근 시 런타임 에러가 발생한다.
greeting[greeting.endIndex] // Error
greeting.index(after: greeting.endIndex) // Error
indices 프로퍼티를 사용해 문자열의 모든 Index에 접근할 수 있다.
let greeting = "Guten Tag!"
for index in greeting.indices {
print("\(greeting[index]) ", terminator: "")
}
// G u t e n T a g !
Array, Dictionary 그리고 Set 등과 같이 Collection 프로퍼티로 만들어진 모든 타입은 index(before:), index(after:), index(_:offsetBy:)를 사용할 수 있다.
Inserting and Removing
특정 인덱스에 하나의 문자만 추가할 때는 insert(_:at:) 메서드를 이용하고
특정 인덱스에 문자열을 추가할 때는 insert(contentsOf: at:) 메서드를 이용한다.
var welcome = "Hello, "
welcome.insert("!", at: welcome.endIndex)
// Hello, -> Hello, !
welcome.insert(contentsOf: "there", at: welcome.index(before: welcome.endIndex))
// Hello, ! -> Hello, there!
삭제는 remove(at:)를 통해 특정 인덱스의 하나의 문자를 삭제할 수 있고
문자열 또는 특정 범위를 삭제하기 위해서 removeSubrange(_:)를 이용할 수 있다.
welcome.remove(at: welcome.index(before: welcome.endIndex))
// Hello, there! -> Hello, there
let range = welcome.index(welcome.endIndex, offsetBy: -6)..<welcome.endIndex
welcome.removeSubrange(range)
// Hello, there -> Hello,
var str = "Hello, World!"
let range2 = str.startIndex..<str.index(str.startIndex, offsetBy: 7)
str.removeSubrange(range2)
// Hello, World! -> World!위 메소드들은 위에서 언급한 모든 Collection 타입에서 사용이 가능하다.
Substrings
문자열에서 prefix(_:)와 같은 메서드를 사용해 Substring을 가지고 오면
또 하나의 다른 String 인스턴스가 아닌 Substring 인스턴스가 된다.
Swift에서 Substring은 String과 거의 동일한 메서드를 가지기 때문에
String과 동일하게 사용하는 데 문제가 없다.
하지만, String과 다르게 String에 대한 작업을 수행하는 아주 짧은 시간 동안 사용한다.
더 길게 사용하고 싶다면 Substring을 새로운 String으로 만들어 줘야 한다.
let greeting = "Hello, World!"
let index = greeting.firstIndex(of: ",") ?? greeting.endIndex
let beginning = greeting[..<index]
let newStr = String(beginning)
String과 마찬가지로 Substring도 메모리를 가지게 되는데 차이점은
Substring은 기존 String이 사용하고 있는 메모리나 다른 Substring이 사용하는 메모리를 사용할 수 있다. (String은 같은 메모리를 공유하면 둘은 동일하다)
이는 기존의 String이나 Substring을 수정하지 않으면 메모리를 복사하지 않기 때문에 성능 낭비를 하지 않을 수 있다.
기존 String의 메모리를 재사용하기 때문에 Substring을 사용하는 동안에는 기존의 전체 String은 메모리에 유지되어야 한다. 즉, Substring은 장기간 사용에 적합하지 않다.
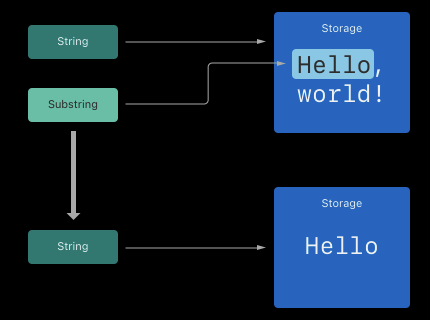
만약 기존의 String이 Hello, World!이고 Substring으로 Hello를 가지고 온다면 Substring은 기존 String의 메모리를 재사용한다.
Substring을 새로운 String으로 생성해 주면 자체적으로 메모리를 가질 수 있다.
Comparing Strings
Swift에는 텍스트 값을 비교하기 위한 세 가지 방법이 있다.
- string and character equality
- prefix equalitty
- suffix equality
String and Character Equality
"equal to" 연산자(==)와 "not equal to" 연산자(!=)를 통해 비교된다.
let quatation = "We're a lot alike, you and I."
let sameQuatation = "We're a lot alike, you and I."
if quatation == sameQuatation {
print("These two strings are considered equal.")
}
Extended grapheme clusters가 동일하면 두 문자열 혹은 문자는 동일하다고 여긴다.
// "Voulez-vous un café?" using LATIN SMALL LETTER E WITH ACUTE
let eAcuteQuestion = "Voulez-vous un caf\u{E9}?"
// "Voulez-vous un café?" using LATIN SMALL LETTER E and COMBINING ACUTE ACCENT
let combinedEAcuteQuestion = "Voulez-vous un caf\u{65}\u{301}?"
if eAcuteQuestion == combinedEAcuteQuestion {
print("These two strings are considered equal")
}
// Prints "These two strings are considered equal"
영어로 사용되는 라틴 대문자는 러시아어로 사용되는 CYRILLIC CAPITAL LETTER A와 동일하게 여겨지지 않는다.
let latinCapitalLetterA: Character = "\u{41}"
let cyrillicCapitalLetterA: Character = "\u{0410}"
if latinCapitalLetterA != cyrillicCapitalLetterA {
print("These two characters aren't equivalent.")
}
// Prints "These two characters aren't equivalent."Prefix and Suffix Equality
hasPrefix(_:)와 hasSuffix(_:) 메서드를 사용해 특정 접두사, 접미사를 포함하는지 확인할 수 있다.
hasPrefix(_:)를 통해 해당 문자열에 해당 접두사를 포함하는지 확인할 수 있다.
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 1 Scene 3: A room in Capulet's mansion",
"Act 1 Scene 4: A street outside Capulet's mansion",
"Act 1 Scene 5: The Great Hall in Capulet's mansion",
"Act 2 Scene 1: Outside Capulet's mansion",
"Act 2 Scene 2: Capulet's orchard",
"Act 2 Scene 3: Outside Friar Lawrence's cell",
"Act 2 Scene 4: A street in Verona",
"Act 2 Scene 5: Capulet's mansion",
"Act 2 Scene 6: Friar Lawrence's cell"
]
var act1SceneCount = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1 ") {
act1SceneCount += 1
}
}
print("There are \(act1SceneCount) scenes in Act 1")
// Prints "There are 5 scenes in Act 1"
hasSuffix(_:)를 사용해 해당 문자열에 해당 접미사가 있는지 확인할 수 있다.
var mansionCount = 0
var cellCount = 0
for scene in romeoAndJuliet {
if scene.hasSuffix("Capulet's mansion") {
mansionCount += 1
} else if scene.hasSuffix("Friar Lawrence's cell") {
cellCount += 1
}
}
print("\(mansionCount) mansion scenes; \(cellCount) cell scenes")
// Prints "6 mansion scenes; 2 cell scenes"
Unicode Representations of Strings
유니코드 문자열이 텍스트 파일 또는 다른 저장소에 저장될 때
유니코드 스칼라는 여러 가지 Unicode-defined encoding forms에 의해 인코딩 된다.
UTF-8(8비트로 인코딩), UTF-16(16비트로 인코딩), UTF-32(32비트로 인코딩)가 있다.
Swift는 문자열의 유니코드를 표현하는 여러 가지 방법을 제공한다.
세 가지의 유니코드 표현 방식으로 String 값에 접근할 수 있다.
UTF-8, UTF-16, UTF-32 표현 방식의 차이
let dogString = "Dog‼🐶"UTF-8 Representation
문자열의 utf8 프로퍼티를 통해 접근이 가능하다.

let dogString = "Dog‼🐶"
for codeUnit in dogString.utf8 {
print("\(codeUnit) ", terminator: "")
}
// 68 111 103 226 128 188 240 159 144 182UTF-16 Representation
string.UTF16View로 UTF-16 표현 방식에 접근할 수 있다.
부호가 없는 16비트(UInt16)로 표현한다.
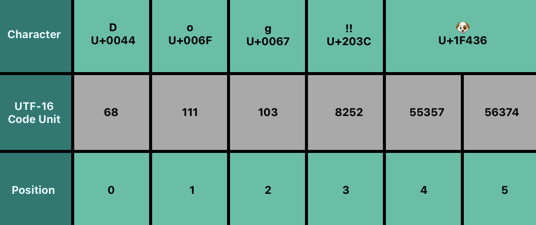
let dogString = "Dog‼🐶"
for codeUnit in dogString.utf16 {
print("\(codeUnit) ", terminator: "")
}
// 68 111 103 8252 55357 56374Unicode Scalar Representation
unicodeScalars 프로퍼티를 통해 접근이 가능하다. UnicodeScalarView 타입이다.
각 UnicodeScalar는 UInt32로 표현되는 스칼라의 21비트 값을 반환하는 value 프로퍼티를 가지고 있다.

for scalar in dogString.unicodeScalars {
print("\(scalar.value) ", terminator: "")
}
print("")
// Prints "68 111 103 8252 128054 "
처음 세 개의 값은 D, O, G 문자를 나타낸다.
네 번째 codeUnit 값(8252)은 16진수 값 203C를 나타내는 십진법이며, (!!)를 나타내는 유니코드 스칼라 U+203C를 나타낸다.
다섯 번째 유니코드 스칼라 128054는 16진수 값 1F435를 나타내는 십진법이며, DOG FACE를 나타내는 유니코드 스칼라 U+1F435를 나타낸다.
value 프로퍼티를 조회하는 대안으로, 각각의 유니코드 스칼라 값은 문자열 보간과 같이 새로운 문자열 값을 구성하는 데 사용될 수 있다.
'Swift 공식 문서' 카테고리의 다른 글
| Control Flow (1) | 2023.12.17 |
|---|---|
| Collection Types (1) | 2023.12.15 |
| Strings and Characters - 1 (1) | 2023.12.08 |
| Basic Operators (2) | 2023.12.05 |
| Assertions and Preconditions (1) | 2023.12.05 |